
I own a Nest security camera. Overall, the experience is fine and I’ve come to appreciate having a security camera at my home. However, my primary issue with the camera is that it continuously streams video. If I had all of the bandwidth I could possibly need then this would be an excellent feature. However, the high-resolution stream causes frequent drops in signal, presumably due to throughput limitations. My current solution is to use a low-resolution stream but it doesn’t capture enough detail.
So I decided to make my own security camera out of a Raspberry Pi. Additionally, I’ve been looking for a reason to actually use the AI tools I create during my day job. My day-to-day work revolves around making and improving AI algorithms but I never get to use them to solve actual problems outside of putting together benchmarks and presentations. Therefore, I decided to make a people-detecting camera.
To address the bandwidth issue mentioned above I only want to record video during “relevant activity”. In this first attempt at the device I define relevant activity to be any footage containing a person. I also want the videos stored somewhere safe and lasting longer than the typical ten to sixty day window that some security camera services offer. I decided to use AWS and store my videos in an S3 bucket. Not a convenient way to access the videos but good enough for an initial attempt.
My Raspberry Pi with 8MP camera module.
I spent a few evenings writing and testing what I call Pinopticon (pie-nopt-icon). 1 Version 1 does three things:
The main recording loop, which I’ve implemented here, is based on the circular stream “advanced example” from the Picamera documentation. The control flow is as follows:
pinopticon/output directory.In the version I have shared above there is much to be desired in this part code. For example, I currently abandon the contents of the circular buffer upon detection, defeating its purpose. I did so because I was observing jumps and jitters in the video near the point where I stitch together the “before detection” and “after detection” windows. However, I learned later that VLC playback of h264 video is “naturally jittery”. This was pretty annoying in that I assumed the jitters were due to insufficient compute power and, as a result, lost some time on the project debugging this non-issue.
At work, a colleague of mine ran a deep learning bootcamp which was designed to expose scientists and engineers in our organization to the key papers in the field. (I have the pleasure of acting as teaching assistant for round two of this bootcamp!) One of these papers is on the Single-Shot MultiBox Detector (SSD) algorithm. While many image classification algorithms assume a single object per-image, SSD will identify multiple objects and their locations. For example, here is a shot of my desk with annotations from SSD.
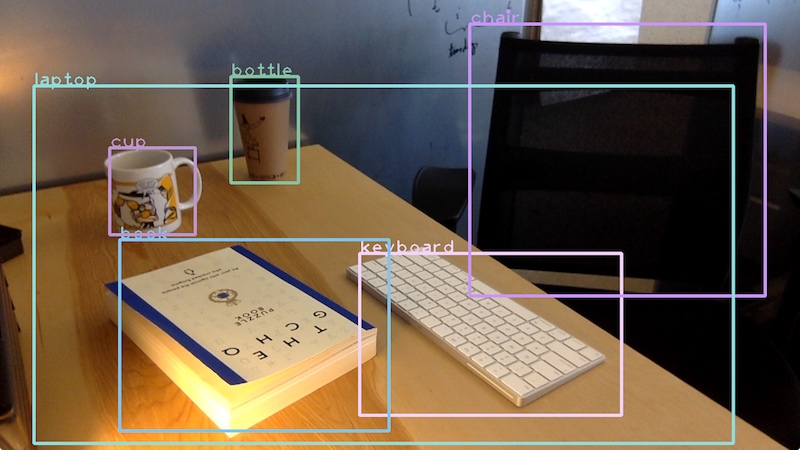
Presumably, desk plus keyboard equals laptop. Also, this image is from a webcam version of Pinopticon I wrote for testing purposes.
For this project I used the MobileNet SSD model, a lightweight variant of SSD for use in small devices. I used a pre-trained model trained on the COCO dataset which can be downloaded for Tensorflow Lite here. Using TFLite and the pre-trained model I created a basic object detector. 2 The code at the link is pretty clear, but I want to highlight a particular part: how to actually pass an image to the object detector.
def detect(self, image, threshold=0.6, verbose=False, **kwds):
image_ = np.array(Image.fromarray(image).resize((300, 300)), dtype=np.uint8)
self._input()[0] = image_
self.interpreter.invoke()
# ...
Here, image is an tensor of integers between 0 and 255
(sometimes called a “quantized image”) where is the resolution of
the camera and each of the RGB channels are provided. 3
After resizing the image I point the input tensor to the data and then run the
model interpreter’s invoke() method. Doing so runs the input data through the
network and populates the output tensors with the results. This is a different
design pattern than the usual “output_tensors = my_network.call(image_)”
format and is one of the ways in which TFLite is different from some other deep
learning frameworks and interfaces.
After that, it’s a matter of parsing the output: mapping the class indices to the corresponding labels and filtering out low-score detections. The latter is important because I don’t want to record video unless the model is reasonable certain that it sees a person and not suggestive combination of shadows.
Finally, I needed a way to automatically push the recordings to my S3 bucket. At
first I thought to incorporate this into the main script but decided to create a
second script that can run concurrently with the main loop.
The script simply periodically checks the pinopticon/output directory for any
files and, if found, pushes them to the specified bucket. A cleaner solution is
to use multi-threaded Python.
All together, you can fire up Pinopticon like so:
$ cd pinopticon
$ python3 pinopticon/main.py &
$ python3 pinopticon/pusher.py BUCKET --sleep 900 --profile PROFILE &
You can’t propose a project like this without doing some cost analysis. It turns out that the cost of storing and accessing ten days worth of video history is similar to that offered by Nest and perhaps slightly cheaper. That being said, I highly value owning my security camera data.
Assuming a 2.5 Mbps bitrate on 720p video we can expect out monthly S3 cost for storing ten full days of video to be,
Also note that this is just the cost store the data. Data retrieval pricing is approximately 1/3rd of the storage cost. If I expect to download my ten-days worth of data to my personal computer at least once per month then we’re essentially at the $10/mo. mark. 4 However, because I’m only storing “active events” ten days worth of video should cover at least a hundred day time span.
As for the up-front cost, a Nest camera starts at $200. A Raspberry Pi starter kit with camera module is approximately $109 with the possibility of cutting costs by using PoE and asking a family member to 3D print a case for you. 5
Modulo some of the issues and design improvements I mention above, the device works pretty well. What’s cumbersome, though, is reviewing the footage afterward. This is in part a UI issue, which means I have an opportunity to learn something new. With the recent SwiftUI announcement the front-end may be easier than I anticipate.
My primary customer (my wife) requests a live feed primarily so we can creep on our cats and dogs during the day. One idea is to detect pets combined with sufficient movement and only stream the video during those periods. 6 To handle this request I will need to look into AWS Elemental MediaConnect and related services.
As for the science part, I’m still thinking of what other types of objects are worth detecting. Or perhaps the Raspberry Pi is capable of running two models at once? There’s a whole host of possibilities I would like to explore.
The panopticon is a type of prison where the inmates are led to believe that they are constantly being watched. In theory, this alone could regulate inmate behavior independently of whether guards actually sit in the observation towers. ↩
The link to the Pinopticon detector points to the state of the detector code at the time of this writing. Things may have changed since then. ↩
I currently have it set to but after learning about the ability to record at multiple resolutions I might be able to record higher resolution video but save the detector some CPU time by feeding it an image closer to the expected size. ↩
Based on these numbers it looks like the subscription rates aren’t the main money-maker for these products. That is, of course, unless the video bitrate is really, really poor and most customers end up not viewing their video feeds. ↩
You know who you are. ↩
Pets spend most of the day sleeping! ↩